-
Faster json converter
Hi all,
Anyone aware of a library I can use for converting K objects to json and vice versa?
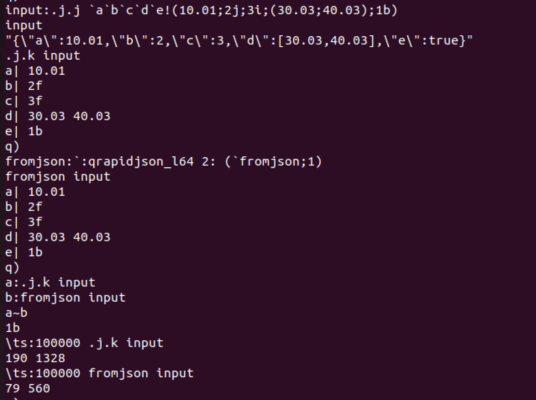
Looking for the equivalent of .j.j and .j.k but faster.
I’ve tried out the qrapidjson library, below, which provides a function for converting K to json, and its about 3-4 times faster on my machine. The github reports it being 48x faster, but to be fair that was 8 years ago, and using an older version of kdb+. I have been testing with v4.1
I’d like to have a faster converted for json to K also, if anyone knows where I could get that? Thanks
https://github.com/lmartinking/qrapidjson
github.com
GitHub - lmartinking/qrapidjson: Faster JSON serialiser for kdb+/q (uses RapidJSON)
Faster JSON serialiser for kdb+/q (uses RapidJSON) - lmartinking/qrapidjson
Log in to reply.