jlucid
Forum Replies Created
-

jlucid
MemberNovember 19, 2024 at 11:49 am in reply to: Help Us Improve Your Experience with the q Language (Survey)‘
-
jlucid
MemberNovember 16, 2024 at 12:19 pm in reply to: Help Us Improve Your Experience with the q Language (Survey) -
Without modifying the existing function, you can reduce the total compute time through parallelisation and the use of multiple threads. Start your process with the -s flag and use peach as shown
.Backtester.Engine peach final_table
I generated your two tables using random data and the threading scales pretty well.
I would say that with queries like this, it would be very helpful for us if you could append sample csv files so that we can quickly load and test potential solutions. Always check that the files dont include client sensitive data before hand, and obscure column data if necessary.
Also, when it comes to optimising functions like this which are critical to your backtesting. Start by making some unit tests with sample data, so that you can be confident that any performance improvements don’t break existing functionality. You could use qspec, k4unit, qunit
-
jlucid
MemberOctober 30, 2024 at 3:03 pm in reply to: Validation on delete in Editable List componentLooking at the arguments to your function, it looks like you are trying to run an update command in a KxDashboards Data Grid component, is that correct?
First of all, to throw an error you can use signal (‘), that what works for me. if[notValidUser;’ErrorMessage];
This should generate a small popup on screen when the user presses submit. Here’s the thing though, the full text “ErrorMessage” may not appear on screen, depending on whether the bug I mentioned below was fixed or not.
I had a similar issue as you in the past, where the error message was being returned but only the first character of the error messages was being displayed (“E” in this case), see link below for issue and fix. I never got a response on this query so I dont know if it was fixed properly in Kx Dashboards.
-
This reply was modified 7 months, 1 week ago by jlucid.
-
This reply was modified 6 months, 2 weeks ago by Carey.

learninghub.kx.com
Dashboards Direct - How to specify an error message on Data Grid edit failure - KX Learning Hub
June 30, 2023 - Dashboards Direct - How to specify an error message on Data Grid edit failure - I have a Data Grid component with Edit mode enabled, users can
-
This reply was modified 7 months, 1 week ago by
-
Yes you need the backtick to amend the fares list. Leaving it out just returns the modified list, which you could then assign to another variable
-
jlucid
MemberOctober 24, 2024 at 11:00 am in reply to: How to use scan to obtain cumulative value of a functionOk so you are saying that you need to cary forward distinct values and apply additional rules to the result? For this you could try using the form v[x;y;z], see https://code.kx.com/q/ref/accumulators/#ternary-values
This will allow you to pass in the columns filtered_levels, low and high when accumulating, so that you can apply additional rules. Below is a simple example using a mock table to demonstrateq)t:([] filtered_levels:((5.0;6.0;8.0;12.0;13.0);(7.0;10.0;11.0);(4.0;5.0;7.0;8.0;9.0)); low:5.0 7.0 4.0;high:13.0 11.0 9.0 )
q)v:{[x;f;l;h] c:distinct x,f;c where c within (l;h)}
q)update cumulative:v[();filtered_levels;low;high] from t
Here the “v” function is not just joining consecutive filtered_levels (and taking the distinct), but also applying logic to the result using low and high values.
code.kx.com
Accumulators – Reference – kdb+ and q documentation - kdb+ and q documentation
An accumulator is an iterator that takes an applicable value as argument and derives a function that evaluates the value, first on its entire (first) argument, then on the results of successive evaluations.
-
Hi Jonathan,
Kx Dashboards is primary designed to allow you to establish connections to running q processes, like RDBs and HDBs, and run queries/functions against them using the datasource mechanism. You can use this to retrieve data or to send a signal to a process.
Now the function you execute on that process could include a system command, which you could use to trigger a script or start another process in the background. But to be honest it’s a messy solution, I’d try to keep kxdashboards purely for querying data if possible, otherwise it could get confusing and hard to maintain very quickly.
What exactly did you want to do?
https://code.kx.com/q/ref/system/
code.kx.com
system is a q keyword that executes a system command.
-
jlucid
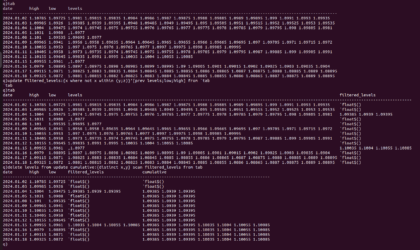
MemberOctober 23, 2024 at 4:03 pm in reply to: How to use scan to obtain cumulative value of a functionTo create the filtered_levels column from the “tab” table I used
update filtered_levels:{x where not x within (y;z)}'[prev levels;low;high] from `tab
which reproduces your screenshot.Then I wasnt sure what you meant by cumulative? Did you mean that you wanted to carry forward
the unique filtered_levels values for each day, like a forward fills (except applied to a list)?
You could use scan to do this using the below
update cumulative:{distinct x,y} scan filtered_levels from tab
-
jlucid
MemberOctober 23, 2024 at 10:10 am in reply to: Clicking a single legend element strikes through allWondering if this issue was fixed? and in what release. Thanks
-
Here is the code generated by LLMs: https://github.com/jlucid/kjson
The original starting point was the qrapidjson library, which provided K to JSON conversion. Most of that code remains unchanged. The main part the model developed is the JSON to K converter.
The first attempt at the JSON to K conversion function was quite buggy.It worked for the simple cases, but failed with more complex ones. To help resolve these bugs, I created a simple unit test script in Q, which the model was able to read, modify, and interpret results from. This was the only code I provided. Having this unittests.q script was critical for the model to recognize when changes broke existing functionality. About 90% of the time, new changes caused previously passing tests to fail (so much for step-by-step thinking).
It took about 100 iterations of 1) modifying C++ code, 2) compiling, 3) pasting compilation errors, 4) running the unit tests, and 5) showing unit test failures and output differences before the model finally developed a base version that passed all tests. I also provided a few examples from the C API documentation, as the model was rusty on that.
Automating many of these steps (2, 3, 4, and 5) using tools like Devin or OpenHands, which can run unit or performance tests itself, would have saved a lot of time.
-
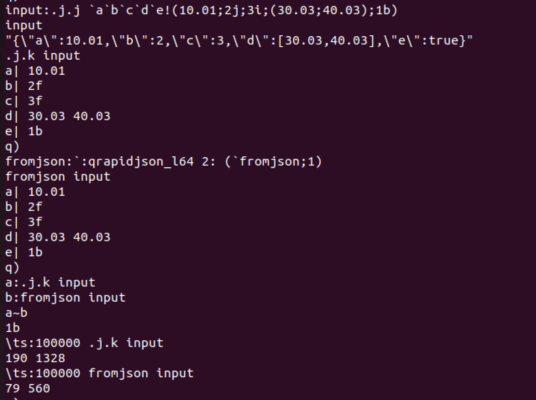
I started by creating json specific message converters using the same library and that worked very well. But then I just asked chatGPT o1-preview to write the equivalent “fromjson” general converter for me, and it worked first time. I’m shocked. I specified to convert numbers without a decimal place to floats just as .j.k does. Attached are some initial results in screenshot. Same output for test json message and faster. All that’s left to do now is submit it to gihub and claim it as my own work :). After all, I was the one who said “do this for me now please”

-
This reply was modified 7 months, 4 weeks ago by jlucid.
-
This reply was modified 7 months, 4 weeks ago by
-
The “cannot write to handle 1” error may be permissions related. Confirm that the folder pointed to by DEVELOPER_DATA has proper write permissions. Perhaps that is why it cannot create the workspace in that folder.
Run: echo %DEVELOPER_DATA% (to check the variable is set correctly)
Then echo Message > “%DEVELOPER_DATA%\test.txt”.
to confirm that you can write a file to that location, or if it throws an error.
-
This reply was modified 8 months ago by jlucid.
-
This reply was modified 8 months ago by
-
Storing the data in a single table for all symbols has its advantages, but the table would need to be sorted by symbol within your date partitioned database, with a parted attribute applied to the symbol column. This is critical if you want to achieve the best query performance when querying by symbol. The question is, how do you get from your in-memory tickerplant table to that on-disk structure. And how do you manage intraday queries. If you are expecting the data to be very large, then I assume you cannot simply store it all in-memory and persist at EOD. Are you planning on having an intraday writer with some sort of merge process at EOD? Something similar to what is described in the TorQ package (see WDB here: https://github.com/DataIntellectTech/TorQ/blob/master/docs/Processes.md)
This design allows you to partition the data by integer intraday, each integer corresponding to a symbol, and then join all those parts together at EOD to create a symbol sorted table. It works well but it does add complexity.Getting back to your current setup, you can parallelise the data consumption by creating additional consumers (tickerplants) where you distribute the topic names across consumers. Alternatively, you could have a single “trade” topic in Kafka but with multiple partitions. For example, if you have 2 consumers and 4 partitions, you can parallelise the consumption of messages, with each consumer reading 2 partitions. That distribution of partitions across consumers will be handled automatically by Kafka, which simplifies things. As opposed to you having to specify explicitly which topics consumer 1 should read, as distinct from consumer 2. The single topic, multiple partition setup, also works well in the event where consumer 1 dies unexpectedly, in which case, consumer 2 will automatically take over reading all partitions. Giving a degree of resilience.
I would suggest taking a read of this Blog post from DataIntellect:
https://dataintellect.com/blog/kafka-kdb-java/In the design presented there, the tickerplant could potentially be removed when you have a Kafka broker in place. The broker is already persisting the data to different partitions (log files) so it provides the recovery mechanism that a tickerplant would usually be responsible for. The subscribers to the tickerplant could simply consume directly from the kafka broker. In this design, your consumers could be intraday writers and RDBs.
github.com
File not found · DataIntellectTech/TorQ
kdb+ production framework. Read the doc: https://dataintellecttech.github.io/TorQ/. Join the group! - File not found · DataIntellectTech/TorQ
-
I’d recommend setting up a proxy, such as Nginx or HAProxy, configured for SSL/TLS termination between external users and your kdb+ application. This setup is typically handled by a network or DevOps engineer. Users would connect securely to the proxy via TLS, and after decrypting the TLS connection, the proxy forwards the request to your kdb+ process over a plain (non-TLS) connection. This approach allows your kdb+ instance to continue operating without the complexities of managing TLS connections directly, while the proxy handles all encryption-related tasks and adds an additional layer of security. Within your kdb+ process, you can then perform checks to determine if the user is in a specify LDAP group or whatever the requirement is.
-
You can use this library by Jonathon McMurrray.
Just load the ws-client_0.2.2.q file into a q session.
This example below shows how to request Top of book messages for BTCUSDThttps://github.com/jonathonmcmurray/ws.q
Note, that because you need a secure connection (for wss), you need to have set the following environmental variables first. Including creation of your SSL certs.
$export SSL_KEY_FILE=/path/to/server-key.pem
$export SSL_CERT_FILE=/path/to/server-crt.pem
$export SSL_VERIFY_SERVER=NO
$rlwrap q ws-client_0.2.2.q -E 2
q)func:{[x] show x}
q).ws.open[
$wss://stream.binance.com:443/ws/btcusdt@bookTicker";func]
{\”u\”:50341952152,\”s\”:\”BTCUSDT\”,\”b\”:\”61344.99000000\”,\”B\”:\”7.60825000\”,\”a\”:\”61345.00000000\”,\”A\”:\”0.04012000\”}”You can parse the messages using .j.k
q).j.k “{\”u\”:50341952152,\”s\”:\”BTCUSDT\”,\”b\”:\”61344.99000000\”,\”B\”:\”7.60825000\”,\”a\”:\”61345.00000000\”,\”A\”:\”0.04012000\”}”
u| 5.034195e+10
s| “BTCUSDT”
b| “61344.99000000”
B| “7.60825000”
a| “61345.00000000”
A| “0.04012000”
github.com
GitHub - jonathonmcmurray/ws.q: Simple library for websockets in kdb+/q
Simple library for websockets in kdb+/q. Contribute to jonathonmcmurray/ws.q development by creating an account on GitHub.